Residual Size is Not Enough for Anomaly Detection: Improving Detection Performance using Residual Similarity in Multivariate Time Series
 Anomaly Scores
Anomaly Scores
Abstract
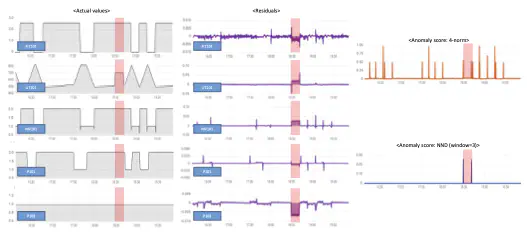
Unsupervised anomaly detection is commonly performed by identifying unusual data samples (or anomalies) from the residual size produced by machine learning algorithms based on normal data (e.g., the residuals of regression models or reconstruction errors of autoencoder models), assuming that anomalies cause large residuals. Unfortunately, anomalies do not always cause large residu- als. Anomaly detection algorithms based on residual size can miss anomalies that cause only small or noisy residuals for each variable in a multivariate time-series. To overcome this issue, we propose “neighbors to residuals” (N2RE), a novel anomaly scoring function based on residual similarity using nearest neighbor distance (NND). Even if residuals of anomalies are small, they show patterns that are different from those of residuals of normal data. Using N2RE can improve anomaly detection performance and reduce the variation in anomaly detection performance due to threshold changes. Experiments with various models on three cyber-physical system datasets verify that N2RE can achieve 19% higher anomaly detection performance than previous approaches without changes to the models.
Yun, Jeong-Han, Jonguk Kim, Won-Seok Hwang, Young Geun Kim, Simon S. Woo, and Byung-Gil Min. 2022. “Residual Size Is Not Enough for Anomaly Detection: Improving Detection Performance Using Residual Similarity in Multivariate Time Series.” In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, 87–96. SAC ’22. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3477314.3506990.